
无处不在的 AI 爬虫,让网站统计越来越不可信
爬虫的进化
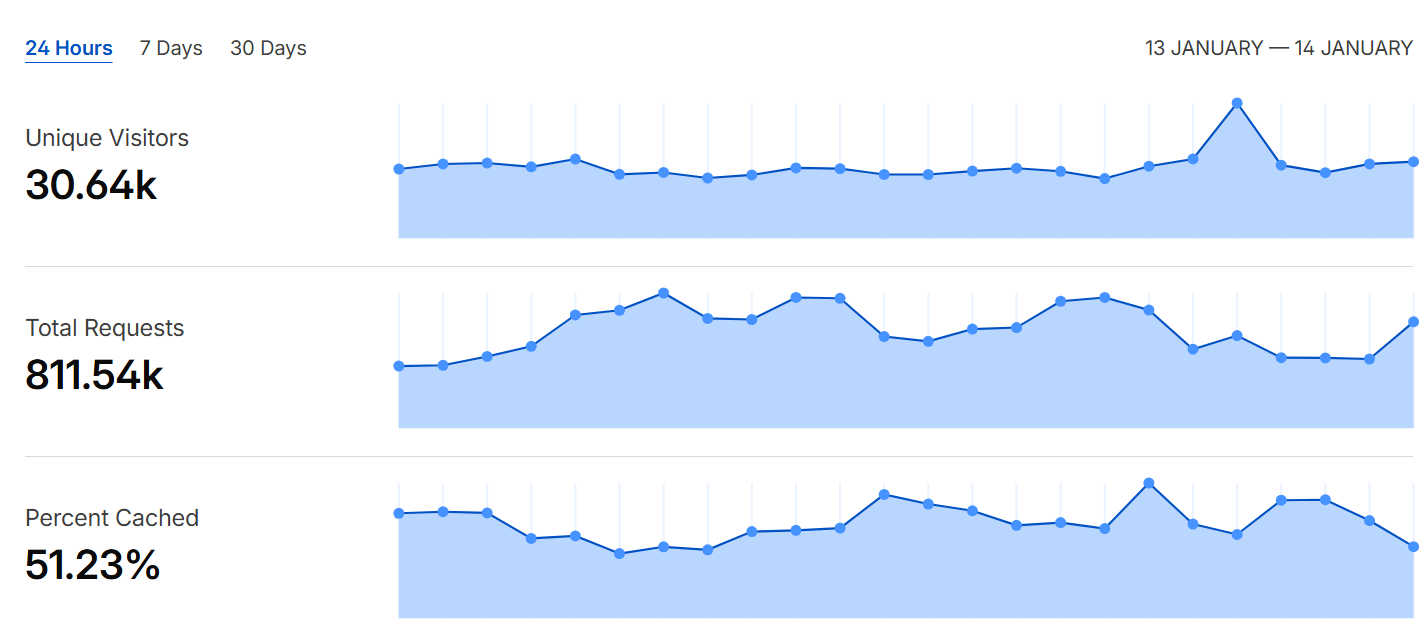
这两年最明显的变化之一,就是 AI 爬虫和各类自动化蜘蛛几乎无处不在。过去网站访问量的波动,往往还能用内容热度、搜索流量、外链传播来解释;但现在很多站长会遇到一种“看起来很繁荣、实际上很空”的数据现象:一天出现几万 IP 的访问记录,日志里请求频率极高、来源分散、行为模式不符合真人浏览,却在统计后台里被当作“访问量”记录下来。
AI让真人判断困难
问题在于:传统统计工具本质上是为“真人浏览器时代”设计的。无论是 PV、UV、Session 还是跳出率,只要爬虫愿意“伪装成浏览器”,带上 UA、执行部分脚本、甚至模拟停留时间,就能在不同程度上污染数据。更麻烦的是,很多 AI 抓取并不会像搜索引擎那样自报家门,它们可能来自云服务、代理池、动态 IP,甚至混在真实用户流量里,让你很难靠简单规则准确过滤。
IP不等于真实访问量
因此,目前几乎没有一个平台能够真正、稳定地统计到网站的真实访问 IP 和真实用户量。你看到的“几万 UV”,可能其中绝大部分都不是潜在用户,而是被动消耗带宽、抓内容、做训练的数据请求。结果就是:站长在做内容策略、投放决策、服务器扩容时,容易被虚假指标误导。
怎么统计IP?
在这种环境下,更可靠的判断方式反而变得“务实”:与其执着于表面的访问量,不如回到业务本质,用 转化率、注册/留资、付费情况、复访与实际订单 来衡量网站价值。换句话说,流量可以被伪造,但 成交与真实行为很难伪造。当统计不再精准,能代表真实用户意图的指标,才是最值得长期跟踪的方向。